

Kimi K2 Just Beat GPT-5, and Nobody Saw It Coming
Exploring how AI is reshaping the way we think, build, and create — one idea at a time

In a ‘David beats Goliath’ moment, Moonshot AI’s Kimi K2 Thinking model has surged ahead of OpenAI’s GPT-5 on several reasoning and agentic benchmarks, including Humanity’s Last Exam. Released in late October 2025, K2 stunned both researchers and industry analysts with its scale, precision, and contextual understanding.
What makes this moment fascinating is the Deja vu it brings. Just months ago, DeepSeek stunned the world by proving that China could build models to rival those of Silicon Valley’s best. Kimi K2 now takes that shock a step further, setting up a whole new front in the global AI rivalry.
Breaking Benchmarks, Bending Expectations
The hype around K2 is there for a good reason. In benchmark tests, Kimi K2 scored 60.2% on BrowseComp versus GPT‑5’s 54.9% and hit 44.9% on the Humanity’s Last Exam (HLE) compared to GPT-5’s 41.7%. It also achieved 85.7% on GPQA Diamond, narrowly surpassing GPT-5’s 84.5%. Impressive numbers.
Beyond raw figures, K2’s architecture is also turning heads. With a 1-trillion-parameter Mixture-of-Experts (MoE) model where only ~32 billion parameters activate per token, it offers a rare mix of high capability and computational efficiency. Moreover, it’s the cost savings that have everyone’s attention: K2’s public pricing starts at $0.15 per 1 M input tokens and $2.50 per 1 M output tokens, significantly cheaper than many rivals.
Additionally, there’s the agentic power: K2 can execute 200–300 sequential tool calls within a multi-step workflow, enabling autonomous reasoning rather than just responding. It also supports context windows of up to 256K or more tokens, making it possible to feed long documents or books into a single prompt.
It already appears to be revolutionary in terms of what an open-source model can deliver.
The Cracks Beneath the Crown
For all its brilliance, Kimi K2 might have a few flaws. Some testers report that while its reasoning is stronger than GPT-5’s on benchmarks, it occasionally struggles with nuance in longer, open-ended tasks, the kind that blend logic with creativity. Its responses can feel overly structured, almost too “safe,” which raises questions about how much freedom the model is actually given to think divergently.
Then again, there’s the accessibility issue. Despite its lower operational cost, Kimi K2 is still largely confined to China’s ecosystem. Global developers and researchers have limited access to its full capabilities, making cross-comparisons tricky and transparency thin. In other words, we’re all impressed, but not everyone has had the opportunity to play with it yet; maybe in a few months, but not right now.
My Perspective: A Turning Point in Intelligence
I’ll admit it; I’m genuinely fascinated by what Kimi K2 brings to the table. I’ve seen models come and go, each claiming to be revolutionary, but this one feels different. I think it’s because I can sense a shift, not just in performance, but in who’s leading the charge.
I see Kimi K2 as proof that innovation is no longer confined to one geography or company. I see a model that’s faster, more efficient, and surprisingly open to developers.
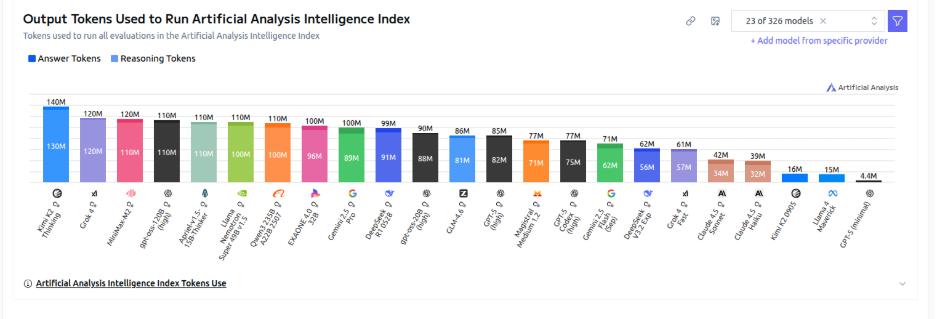
According to Artificialanalysis.ai’s latest evaluation, Kimi K2 Thinking generated the highest volume of output tokens: a total of 140 million, with 130 million dedicated to reasoning alone. That’s more than any other leading model, including Grok 4, Minimax M2, and GPT-5. While token count doesn’t directly equate to intelligence, it’s a strong indicator of reasoning depth and verbosity. In simpler terms, Kimi K2 is thinking out loud more than anyone else in the room, showing how aggressively it tackles complex problems compared to its peers.
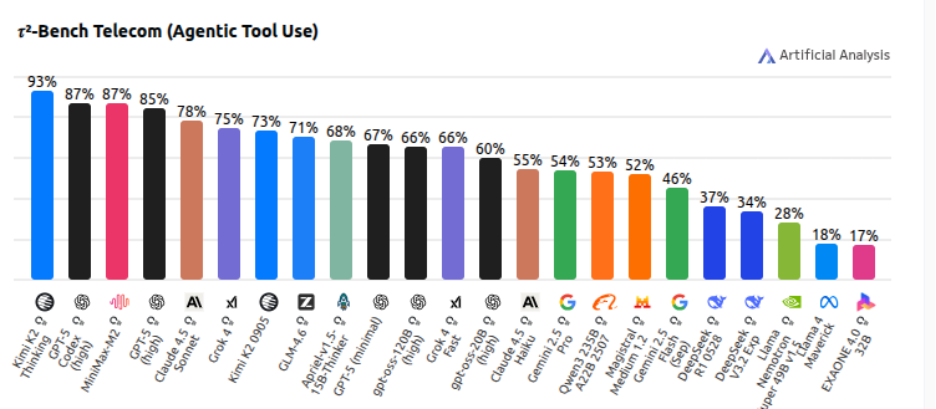
Moreover, in the τ²-Bench Telecom (Agentic Tool Use) benchmark, it takes the lead with an impressive 93% score, outperforming major models like Claude 3.5 Pro, GPT-4.1, and Grok 4.
And I see what that means for the rest of the world: a wave of competition that might finally make AI more accessible and affordable for everyone. Moreover, for me at least, this also changes the narrative. For years, the world has been watching OpenAI, Anthropic, and Google set the pace. But now, I see the center of gravity tilting. There apparently is a future where brilliance is built and distributed everywhere.
Even though I’m not sure if Kimi K2 will hold the crown for long, I’m sure it’s lit a fire. And it’s exciting to see where that spark leads next.
AI Toolkit:
Runable — A design-driven general AI agent that executes any digital task, building apps, reports, or media, through natural language commands and deep app integrations.
Simbli — An intuitive AI platform with specialized agents that simplify everyday work, automating content, communication, and operations with zero technical setup.
Bika.ai — A creative AI studio that generates and manages brand content, from visuals to marketing assets, powered by intelligent automation.
The Librarian — A smart knowledge companion that organizes, summarizes, and retrieves information from your files and web sources instantly.
Prue.ai — A research-focused AI assistant that helps you analyze, write, and ideate with precision and clarity.
Prompt of the Day: Benchmark Your AI Brilliance
I want you to act as an AI performance evaluator. I’ll give you a task, and you’ll perform it twice, once using your most efficient reasoning, and once using your most creative reasoning.
After completing both, explain:
Which version performed better and why.
How your reasoning or tone changed between the two.
What reveals the trade-off between speed, accuracy, and creativity.